Когда нужно быстро выкачать исходники сайта с сервера, даже относительно быстрый SSH тонель не дает нужной скорости. И ждать приходиться очень и очень долго. А еще многие хостинг провайдеры не предоставляют этого доступа, а заставляют довольствоваться FTP, который в разы медленнее.
Лично для себя я определил выход. На сервер закачивается небольшой скрипт и запускается. Через некоторое время получаем архив со всеми исходниками. А один файл, даже по древнему FTP качается гораздо быстрее нежели сотня маленьких.
Ранее на страницах этого блога библиотека zipArchive . Однако, тогда речь шла о распаковке архива.
Для начала, нам потребуется узнать, есть ли на сервере поддержка zipArchive. Это популярная библиотека установлена на подавляющем числе хостингов.
Библиотека жестко ограничена параметрами php и сервера. Огромные базы и банки фотографий заархивировать не получится. Даже базы старой доброй программы 1С для бухгалтерии . Казалось бы в них должны быть лишь текстовые данные. Но нет.
Советую использовать библиотеку, лишь при архивировании относительно небольших сайтов, с огромным числом мелких файлов.
Проверим доступна ли работа с библиотекой
If (!extension_loaded("zip")) { return false; }
Если все хорошо, скрипт продолжит свое выполнение дальше.
Небольшой оффтоп, для таких проверок. Проверки стоит делать именно так, избегая больших конструкций с вложенными скобками. Так код будет более атомарным, и легко будет поддаваться отладке. Сравните
If(a==b){ if(c==d){ if(e==f){ echo "Все условия сработали"; }else echo "e<>f"; }else echo "c<>d"; }else echo "a<>b;
и такой код
If(a!=b) exit("a<>b); if(c!=d) exit("c<>d); if(e!=f) exit("e<>f); echo "Все условия сработали";
Код приятнее и не разрастается на огромные вложенные конструкции.
Простите за оффтоп, но хотелось поделится этой находкой.
Теперь создадим объект и архив.
$zip = new ZipArchive(); if (!$zip->open($destination, ZIPARCHIVE::CREATE)) { return false; }
где $destination - это полный путь до архива. Если архив уже создан, то файлы будут в него дозаписываться.
$zip->addEmptyDir(str_replace($source . "/", "", $file . "/"));
где $source это полный путь до нашей категории (которую мы изначально архивировали), $file - это полный путь до текущей папки. Это сделано для того, чтобы в архиве не было полных путей, а лишь относительные.
Добавление файла работает похожим образом, но нужно сперва прочитать его в строку.
$zip->addFromString(str_replace($source . "/", "", $file), file_get_contents($file));
В конце надо закрыть архив.
Return $zip->close();
Как пробежать все файлы и поддиректории в папке, думаю объяснять не надо. Погуглите, что-то вроде Рекурсивный обход папок на php
Мне подошел такой вариант
Function Zip($source, $destination){ if (!extension_loaded("zip") || !file_exists($source)) { return false; } $zip = new ZipArchive(); if (!$zip->open($destination, ZIPARCHIVE::CREATE)) { return false; } $source = str_replace("\\", "/", realpath($source)); if (is_dir($source) === true){ $files = new RecursiveIteratorIterator(new RecursiveDirectoryIterator($source), RecursiveIteratorIterator::SELF_FIRST); foreach ($files as $file){ $file = str_replace("\\", "/", $file); // Ignore "." and ".." folders if(in_array(substr($file, strrpos($file, "/")+1), array(".", ".."))) continue; $file = realpath($file); $file = str_replace("\\", "/", $file); if (is_dir($file) === true){ $zip->addEmptyDir(str_replace($source . "/", "", $file . "/")); }else if (is_file($file) === true){ $zip->addFromString(str_replace($source . "/", "", $file), file_get_contents($file)); } } }else if (is_file($source) === true){ $zip->addFromString(basename($source), file_get_contents($source)); } return $zip->close(); }
Каждый сайт - это история, которая имеет начало и конец. Но как проследить этапы становления проекта, его жизненный цикл? Для этих целей существует специальный сервис, который именуется веб-архивом. В этой статье мы поговорим о представлении подобных ресурсов, их использовании и возможностях.
Что такое веб-архив и зачем он нужен?
Веб-архив - это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие - открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции. Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Как использовать веб-архив?

Как уже отмечалось выше, веб-архив - это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Проекты, предоставляющие историю сайта

Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Возможности использования веб-архивов

Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива

Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта

Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URL
https://www.nic.ru/auction/forbuyer/download_list.shtml#buying в строку поиска. - На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата , это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Понятно, что создателям шаблонов проще стандартными функциями и тегами шаблонов WordPress вывести стандартные виды всех страниц сайта, но это создает единообразие внешнего вида и ощущение перехода на одни и те же страницы сайта .
Сразу покажу, что получим в результате.
Вид архивов wordpress: архив рубрик до измения
 Архив рубрик с убранными миниатюрами и ссылкой подробнее.
Архив рубрик с убранными миниатюрами и ссылкой подробнее.
Важно! Так как данная задача решается изменением кода шаблона, то перед работами делаем (базу данных+файлы сайта). В дополнении, делаем две копии рабочего шаблона, одну для правки, вторую для восстановления неправильной правки.
Меняем внешний вид архивов WordPress
Чтобы изменить внешний вид архивов WordPress, нужно найти, вернее, определить, какой файл в вашем рабочем шаблоне выводит архивы. В большинстве шаблонов все архивы выводятся единым файлом, называется он (archive.php).
Повторяюсь, для безопасности потерять сайт, не используем редактор в административной панели сайта, а правим заранее сделанные резервные копии файлов шаблона.
В текстовом редакторе (типа Notepad++), открываем файл archive.php и начинаем правку. В файле archive.php (в конце файла) ищем функцию, выводящую блог архива:

Имя это имя файла, который используется для вывода блога архивов.
Первая идея выполнения задачи проста : нам нужно поменять код файла выводящего архивы (content.php), а именно, убрать в нем несколько функций, и тем самым сменить внешний вид всех архивов сайта (рубрик, авторов, дат и т.д.).
Но возникает вопрос, если мы поменяем код файла шаблона, он вернется в прежнее состояние после первого обновления шаблона, нам это не нужно. Поэтому, мы не будем редактировать файл content.php, а копируем его и создаем свой файл, под другим названием, например content-cat.php и редактируем его .
Ищем в файле функцию, выводящую миниатюры. Функция вывода миниатюр будет вверху. Убираем вывод миниатюры.

или и убираем строку с ‘Read More’, ‘название шаблона’.

Созданный и отредактированный файл content-cat.php сохраняем и заливаем в каталог сайта в папку рабочего шаблона. Этот файл появится в административной панели сайта на вкладке Внешний вид→Редактор.
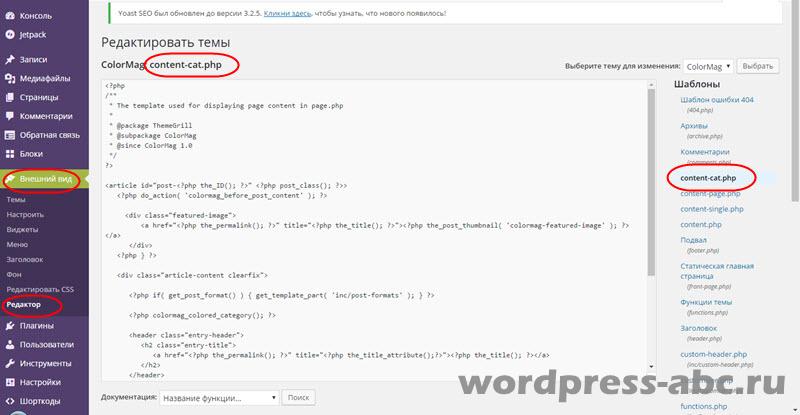
Переходим ко второму шагу. В файле, который выводит архивы (archive.php), меняем название файла content на content-cat .

Сохраняемся и смотрим результат. Если, что те не так, система покажет ошибку, файл ошибки и строку ошибки. Для исправления ошибки, сохраненные резервные файлы шаблона возвращаем на место и повторяем все заново.
Совет. Если хотите почитать больше, о тегах шаблонов и стандартных функциях WordPress, обратите внимание на этот сайт: https://wp-kama.ru . Это не реклама и даже не ссылка, этот сайт понятнее, чем официальный сайт WordPress, в разделе тегов шаблонов и функций.
В развитие темы
По-моему, тема анонсов на сайтах WordPress требует продолжения. В ближайших постах, проговорю темы: и .
WordPress Codex
Скрытый текст
Функция the_post_thumbnail
Функция
the_post_thumbnail
Назначение
Функция the_post_thumbnail выводит html код картинки-миниатюры поста пустое значение, если картинка отсутствует.
Применение
Этот тег шаблона, функция the_post_thumbnail, должен использоваться внутри
Использование
the_post_thumbnail(string|array $size = "post-thumbnail", string|array $attr = "")Источник
Файл: wp-includes / post-thumbnail-template.php
Function the_post_thumbnail($size = "post-thumbnail", $attr = "") { echo get_the_post_thumbnail(null, $size, $attr); }
Параметры
$size (строка/массив)
Размер миниатюры, которую нужно получить. Может быть строкой с условными размерами: thumbnail, medium, large, full или массив из двух элементов (ширина и высота картинки): array(60, 60).
По умолчанию : ‘post-thumbnail’, то есть размер который устанавливается для текущей темы функцией set_post_thumbnail_size()
$attr (строка/массив)
Массив атрибутов, которые нужно добавить получаемому html тегу img (alt - альтернативное название).
По умолчанию :